Reading through comic archives is fun, but usually quite time consuming. Sometime last year I was thinking that an archived comic each day that XKCD didn't have a new one would be a great way to read through the archives on an ongoing basis. I looked a couple times, but never saw anyone else doing that. Yesterday I finally got around to writing the scripts to grab and post the appropriate data, and published a Daily XKCD Archive feed. Each regular non-posting day the next comic in the archive is posted, providing some form of XKCD comic daily. Provided the current posting schedule is kept it should catch up to current comics in about 3 years, at which point it'll start at the beginning again. Hopefully other people will enjoy this feed too.
I was told I needed to retrieve a present left for me, and that the person wanted to know my reaction. Can you guess who gave this to me?

I've repeatedly been told I need to try it for a long time now (at least a year) by Nick and others, and I guess this is the next step in that process. I've never been a gamer, but apparently I look like one (or at least like I would know what Up-Up-Down-Down-Left-Right-Left-Right-B-A-Start meant - an area in which you apparently failed, JoeBuck).
This is an interesting new site for throwing out questions to the Internet. Automatically tracking the site name across Twitter and Technorati is an interesting way to gather the requests, but also appears to be producing a lot of noise (such as whenever someone talks about the site). It'll be interesting to see how much filtering can be done to keep S/N good, especially when a lot of S could be considered N. Currently it looks like something I couldn't watch consistently due to the flood of posts.
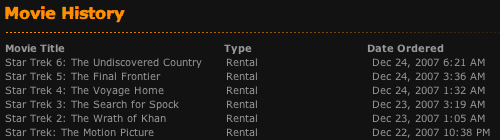
What better way to start a long break than with a bunch of geeky entertainment? So far this weekend I've gone through all 6 of the original Star Trek movies, plus Joe Buck and I have watched half the first season of Battlestar Galactica. Now I just have to wait until Wednesday for the second half of the season...
Detecting Spam with Regular Expressions, posted last week on the SANS site. It's a really interesting read about an idea for detecting spam, although generating the patterns takes a lot of CPU time.
I wonder what adding a new generation on given time intervals (or when x amount of new data is generated) and feeding it the new data each time would do to the reliability of the algorithm. I don't see it in the paper, but the technique seems to work with genetics. Just skimming the example code and ideas without thinking too much about them it appears possible to at least try. I wonder if it'd suffer the same issues a lot of Bayesian implementations do where the quality of filtering goes down. Filtering new input by similarity to existing data (or by similarity to the opposite data set) might be helpful. Anyone want to experiment and post the results?
There was also a comparison of the economies of Corn vs Cane Ethanol, men who care about college sports, phosphoric acid and metabolic acidosis, and something about major drugs of abuse.
All as seen on TV tonight, so I can't say anything about accuracy. Except apparently that first one.
That'd be the short title of a new bill introduced Friday, which says (pages 411-412) schools shall to the extent practicable
, develop a plan for offering alternatives to illegal downloading or peer-to-peer distribution of intellectual property as well as a plan to explore technology-based deterrents to prevent such illegal activity.
It also says (p412) there may be grants to schools for related things including cost-effective technological solutions
. Besides possibly only applying to the deterrents and not alternatives, it's a competitive process which really means it's an unfunded mandate for many (most?) schools. Still not what I want my tax dollars going towards. While the arguments for education on copyright and legalities of sharing things for which they don't have permission could be valid, forcing providing alternatives and technology to attempt to stop it is ridiculous. With the way things are already moving as existing technological measures are implemented and improved, there will be no way to tell the difference between legitimate and illegal p2p transfers (unless one is a party in the transfer). Anything built to stop illegal transfers will have negative effects on legitimate activities.
There's a bit of an article about it at CNET too.
Copyright ©2000-2008 Jeremy Mooney (jeremy-at-qux-dot-net)

{kind=link}