remarks: *************************************************************
remarks: * *
remarks: * For issues of abuse related to this IP address block, *
remarks: * including spam, please send email to at <netblock>: *
remarks: * *
remarks: * goodnews@<domain> *
remarks: * *
remarks: *************************************************************
Since when are abuse reports good news?
Detecting Spam with Regular Expressions, posted last week on the SANS site. It's a really interesting read about an idea for detecting spam, although generating the patterns takes a lot of CPU time.
I wonder what adding a new generation on given time intervals (or when x amount of new data is generated) and feeding it the new data each time would do to the reliability of the algorithm. I don't see it in the paper, but the technique seems to work with genetics. Just skimming the example code and ideas without thinking too much about them it appears possible to at least try. I wonder if it'd suffer the same issues a lot of Bayesian implementations do where the quality of filtering goes down. Filtering new input by similarity to existing data (or by similarity to the opposite data set) might be helpful. Anyone want to experiment and post the results?
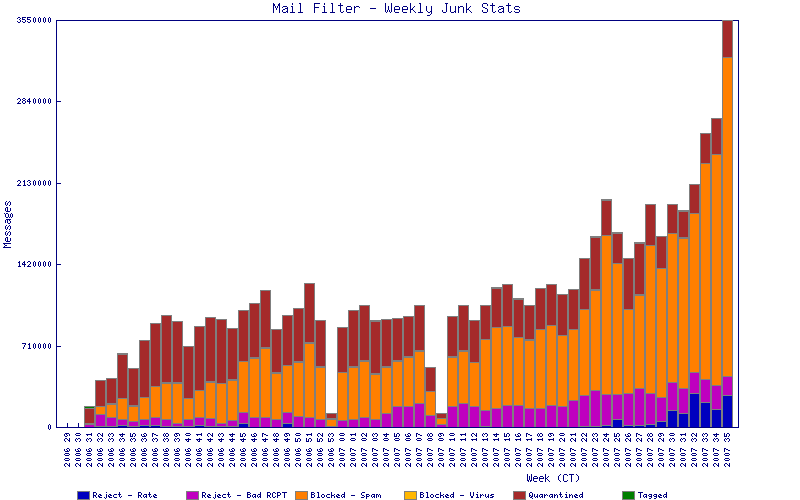
This was the first week of school, but for comparison legitimate mail rose maybe 10% W-F and 20% over the weekend. I was thinking it was getting bad the week before. Hopefully it was just compromised machines again being online, and it'll go down and they get cut off and cleaned.
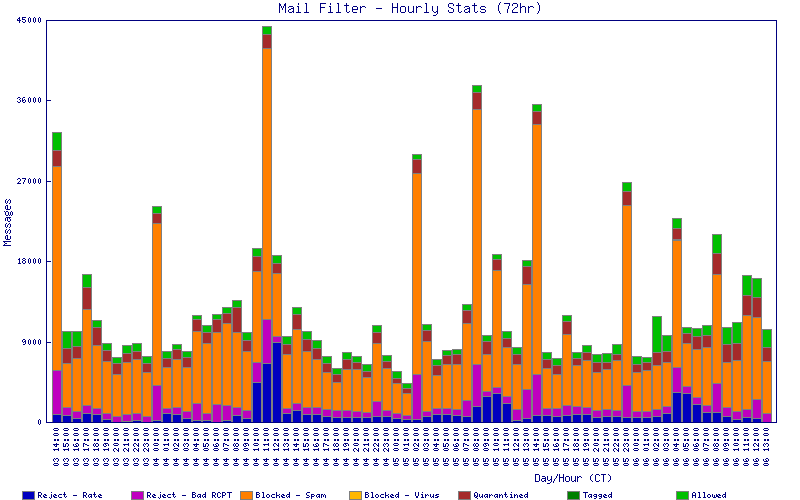
Apparently they tried a few bigger runs this weekend. At least the BLs stopped them quickly.
^Received: from (\w+(\d+)\.\w+\.\w+) \(\1 \[\d+\.\d+\.\d+\.\2\]\)
Copyright ©2000-2008 Jeremy Mooney (jeremy-at-qux-dot-net)